Posting this query on behalf of client. Account: Megaannum Technology Limited Contact: Teddy Chiu Please see additional query below.
In addition, I find that if I search `Elon Musk` on workspace, it will return the news/data from X, how do I get these news/data from X via the function call?
The main question is that the retrieved news by get_headlines() doesn't include the ric, for example, it has `versionCreated`, `headline`, `storyID`, `sourceCode` only, how can I know the news related to which tickers or companies? Taking above mentioned query with `Elon Musk` as an example, it also return me those 4 field without the `ric` field, without a `ric` field with value `TSLA.O`
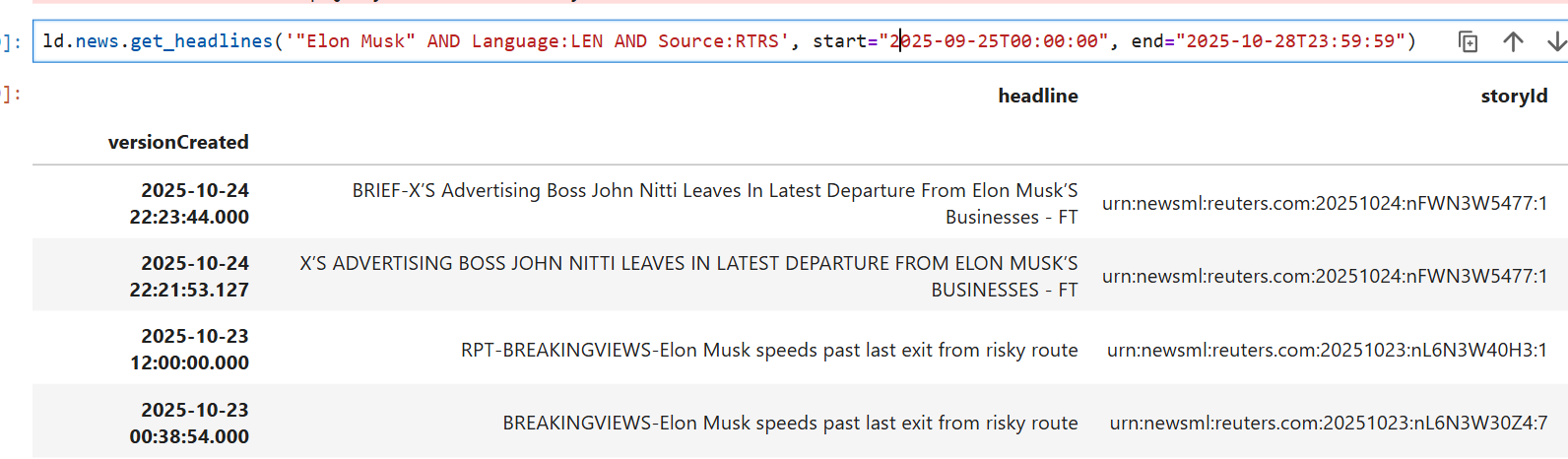
Moreover, I try ld.news.get_headlines("'Elon Musk' AND Language:LEN AND Source:RTRS", start="2025-09-25T00:00:00", end="2025-10-28T23:59:59"), just difference query. And I find that it return empty while this is not possible since I just google Reuters Elon Musk, it already show me there is some news relate to Elon Musk today
Looking forward to your response team. Thanks in advance.
@arcuss
Thank you for reaching out to us.
The Source:X may not be available from the API. Please check this discussion. I tested it an it still doesn't work.
You can access the raw news response by using the Content layer - News example.
response = news.headlines.Definition('"Elon Musk" and LEN', count=10).get_data() response.data.raw
The _qcode with the "R:" prefix will represent a RIC.
{'_qcode': 'R:TSLA.O'},
Please try this one:
ld.news.get_headlines('"Elon Musk" AND Language:LEN AND Source:RTRS', start="2025-09-25T00:00:00", end="2025-10-28T23:59:59")
Thanks for checking this, @Jirapongse
I'll relay this to the client, and I'll let you know if there will be any follow ups. Have a
My question is that can the output of
also return the field of 'ric'? For example, the query
'"Elon Musk" AND Language:LEN AND Source:RTRS
will return the English news from RTRS related to Elon Musk with the field: versionCreated, headline , storyID, sourceCode. I'm asking that can it also return a field like ric which valued in TSLA.O.
versionCreated
headline
storyID
sourceCode
ric
TSLA.O.
@Teddy
The data frame returned by the ld.news.get_headlines doesn't contain a column for RIC.
You need use the news.headlines.Definition method to retrieve the raw response, and then create a new data frame from that raw data. For example:
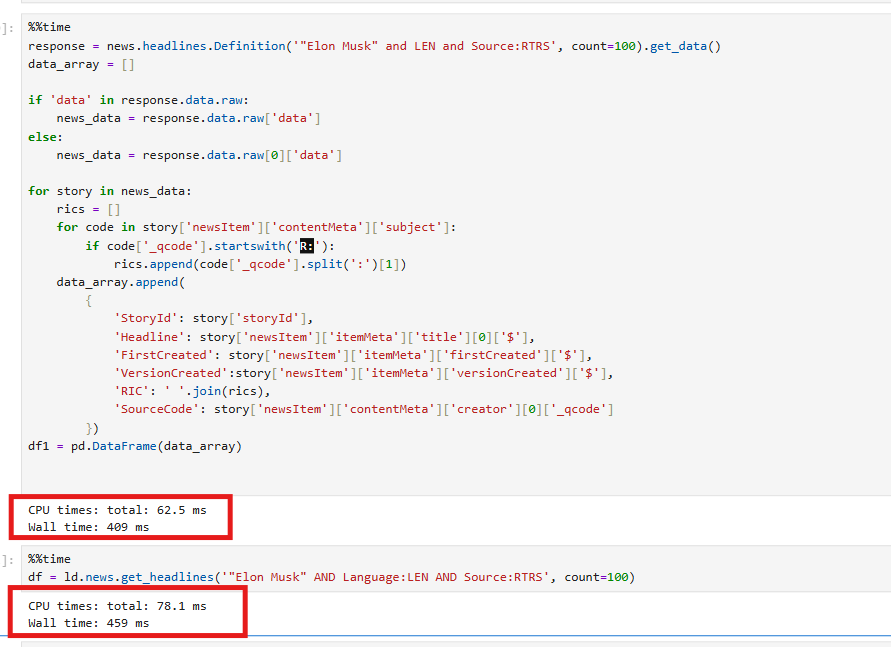
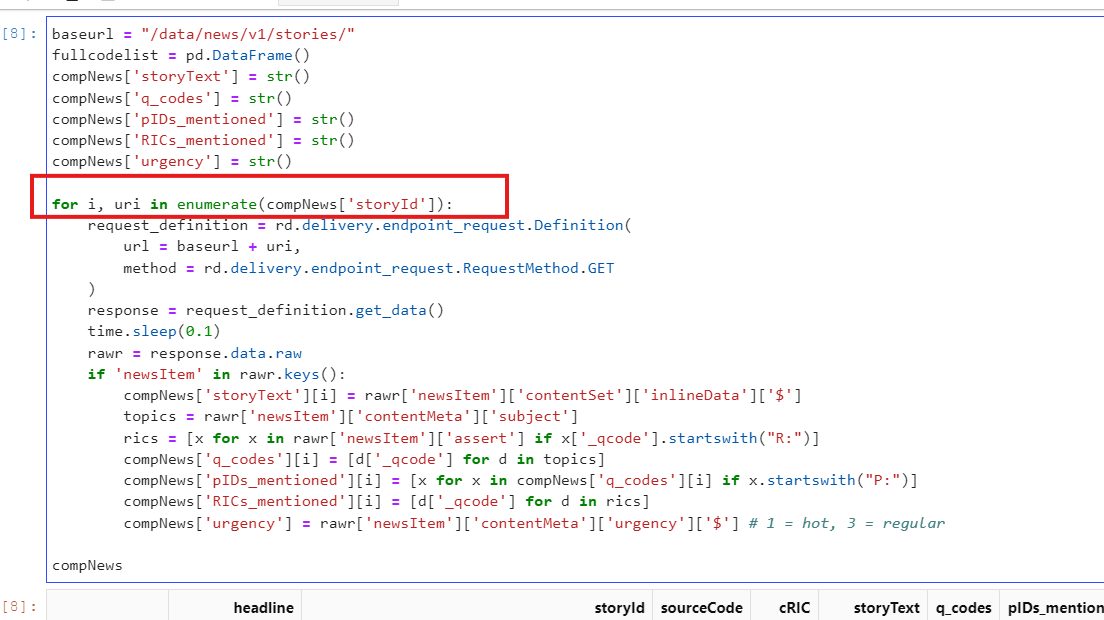
import pandas as pd response = news.headlines.Definition('"Elon Musk" and LEN and Source:RTRS', count=100).get_data() data_array = [] if 'data' in response.data.raw: news_data = response.data.raw['data'] else: news_data = response.data.raw[0]['data'] for story in news_data: rics = [] for code in story['newsItem']['contentMeta']['subject']: if code['_qcode'].startswith('R:'): rics.append(code['_qcode'].split(':')[1]) data_array.append( { 'StoryId': story['storyId'], 'Headline': story['newsItem']['itemMeta']['title'][0]['$'], 'FirstCreated': story['newsItem']['itemMeta']['firstCreated']['$'], 'VersionCreated':story['newsItem']['itemMeta']['versionCreated']['$'], 'RIC': ' '.join(rics), 'SourceCode': story['newsItem']['contentMeta']['creator'][0]['_qcode'] }) df = pd.DataFrame(data_array) df
How many request this code cost?
This counts as one request. The maximum limit of news headlines per response is 100.
One request can request at most 100 news headlines.
Can I know what's the difference between ld.news.get_headlines and news.headlines.Definition
ld.news.get_headlines
news.headlines.Definition
The ld.news.get_headlines is in an access layer which provides a high level interface for ease of use so it returns only a data frame.
The news.headlines.Definition is in a content layer which can return raw data. It is for advanced usage.
Under the hood, both interfaces connect to the same news service to get news headlines and I believe that the ld.news.get_headlines internally uses the news.headlines.Definition to retrieve data.
The working principle of the news.headlines.Definition is same as ld.news.get_headlines? I saw the provided code is quite long and have 2-for loop
The returned data frame doesn't have the RIC column.
If you want the RIC column, you need to parse raw JSON content and create a new data frame that has the RIC column. I have created a sample code for demonstration.
data_array = [] if 'data' in response.data.raw: news_data = response.data.raw['data'] else: news_data = response.data.raw[0]['data'] for story in news_data: rics = [] for code in story['newsItem']['contentMeta']['subject']: if code['_qcode'].startswith('R:'): rics.append(code['_qcode'].split(':')[1]) data_array.append( { 'StoryId': story['storyId'], 'Headline': story['newsItem']['itemMeta']['title'][0]['$'], 'FirstCreated': story['newsItem']['itemMeta']['firstCreated']['$'], 'VersionCreated':story['newsItem']['itemMeta']['versionCreated']['$'], 'RIC': ' '.join(rics), 'SourceCode': story['newsItem']['contentMeta']['creator'][0]['_qcode'] }) df = pd.DataFrame(data_array) df
The part that is used to get news headlines is only one line.
response = news.headlines.Definition('"Elon Musk" and LEN and Source:RTRS', count=100).get_data()
What about the time complexity? The speed will be longer than using get_headlines?
If we don't count the for/loop part, it should be the same.
I tested it, and there isn't much difference.
Can I ask what field will be included in the raw JSON content?
The raw data is in this field.
response.data.raw
Please check the code.
The output looks like this:
For the StoryID: urn:newsml:reuters.com:20251018:nFWN3VZ02U:1, It shows SourceCode is from RTRS, while I use news.get_story, it redirect me to the X, why the source is RTRS instead of X? This related to my previous question asking about how to fetch news from X.
I think you mean this news.
The news monitor also displays it as RTRS. You need to contact the helpdesk team via LSEG Support to verify this.
Currently, the "Source:X" news query is not supported by the API.
Thank you so much, I will contact the helpdesk. Moreover, I want to ask about is the VersionCreated is in UTC right?
Yes, it is UTC.
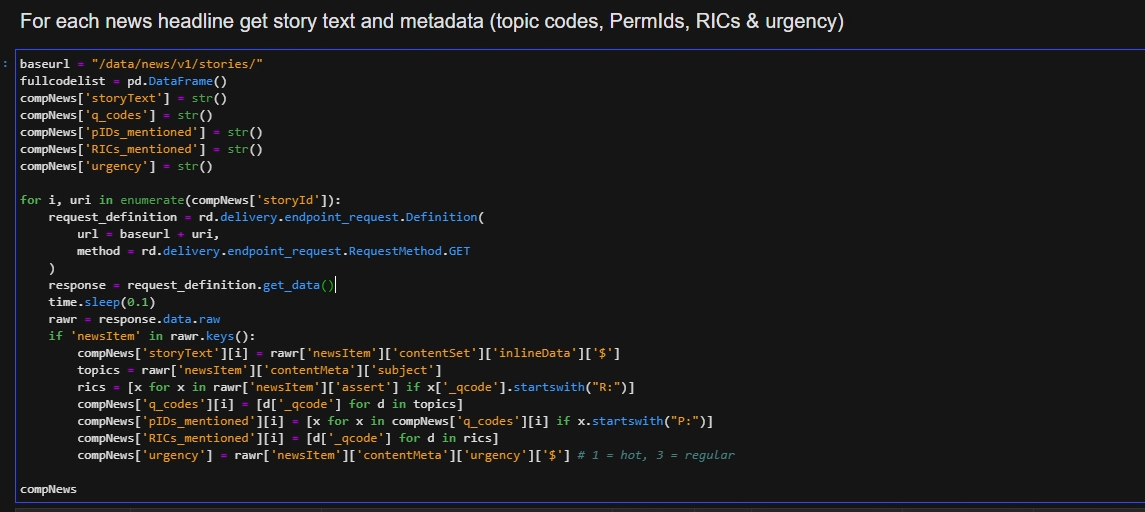
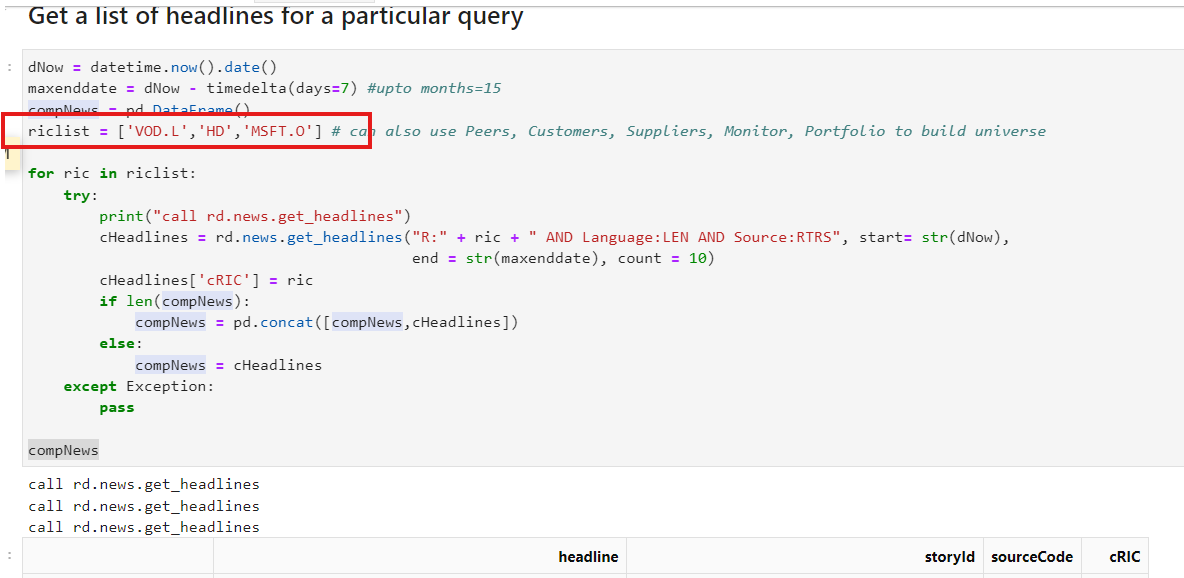
I found this sample code on workspace. I want to know how many request this code will be used?
The first code is retrieving news headlines.
The number of requests depends on the number of items in the ricList. In the example, there are 3 RICs. Therefore, it uses 3 requests to get news headlines for those three RICs.
Then, the API returns 27 news headlines.
Then, the following code retrieves stories for those 27 news headlines so it uses 27 requests.
Totally, it uses 30 requests to get news headlines and stories.
In summary, it depends on the number of items in the ricList and the number of the returned news headlines for those RICs.