Hi,
We are trying to migrate to TickHistory v2 using the REST API in .Net C#.
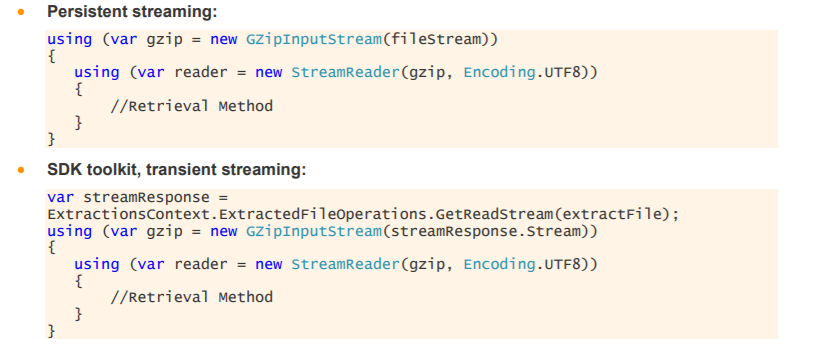
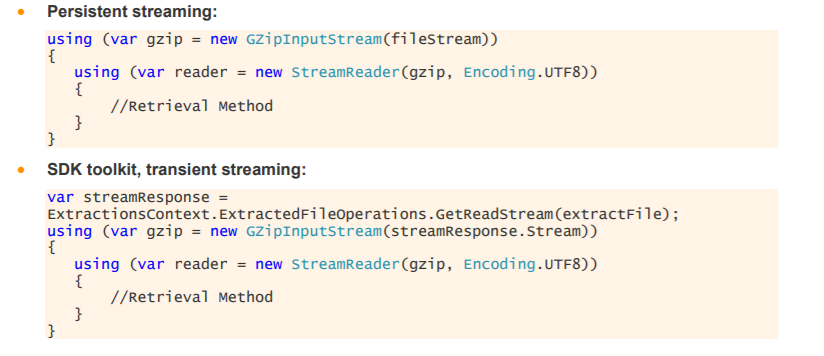
Currently we are retrieving a gzip file containing the following information for each Equity Spot. But when I set AutoDecompression option on ExtractionContext to true, then in the received file (.csv file) I do not receive all the instruments I have specified. But if I do not set this option AutoDecompression then I do receive all the instruments in the received zip file (gz file for example). The template I am using is TickHistoryTimeAndSaleExtractionRequest.
Do you know the reason for this?
Thanks.


{kind=link}