help
How do request file size on a Refinitiv server via REST API?
At the forum gave advice, to look through the DataScope. What if I download a historical data on individual days and such files thousands? For example, I want to download RIC for 9 years. But download not 1 file, download for 1 day (StartDate_EndDat=1 day)
Creating thousands of reports per DataScope for thousands of days to view the size of each file is not effective.
How do I request file size information through the REST API?
I want to automate the entire process in order to know for sure that when downloading information is not lost.
For example, I downloaded RIC, it weighs 23 Gb, but I know that other RIC by this symbol, the average file size is 50 Gb.
Every time look at DataScope? Not an effective waste of time ((Must be some way through REST API

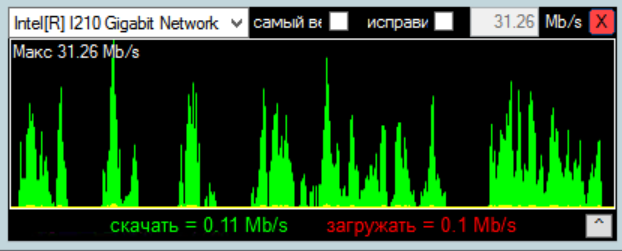
download speed is not stable.
I have 10 Gb\s Internet.
The actual speed download can be 90 mb\s and then up to 0.01 mb\s
The forum wrote that historical data is stored on AWS
If the Internet speed is high, then you can download very quickly.
Practice shows that the information is not true.
During working days, download speed decreases to 0.01 mb\s - 2 mb\s for many hours, even if 10 gb\s Internet.
It is not possible to download historical data efficiently and quickly.

