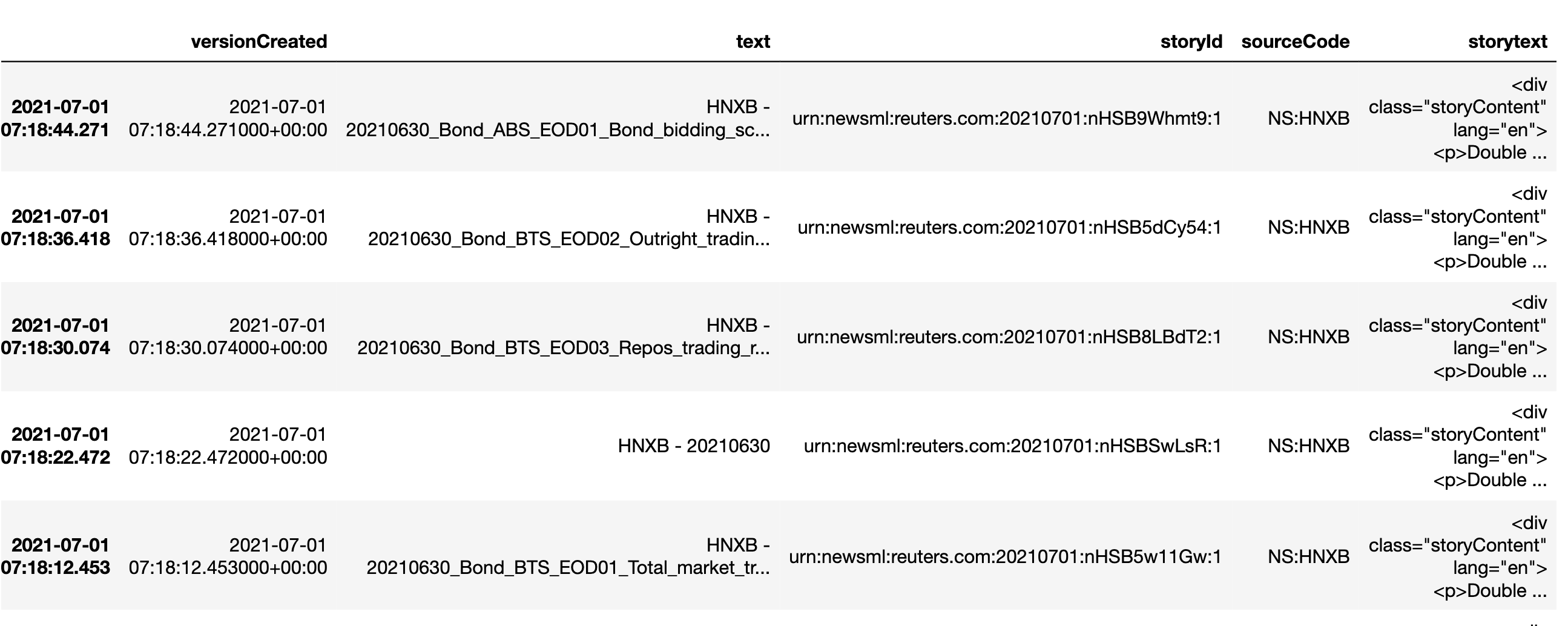
In Eikon, news code [HNXB] contains headlines with links to download the file. Is there a way for us to download the data frame directly via Codebook? I'm only able to get the headlines but couldn't find a code that would extract the data directly.
ek.get_news_headlines(query = 'HNXB', count=10)

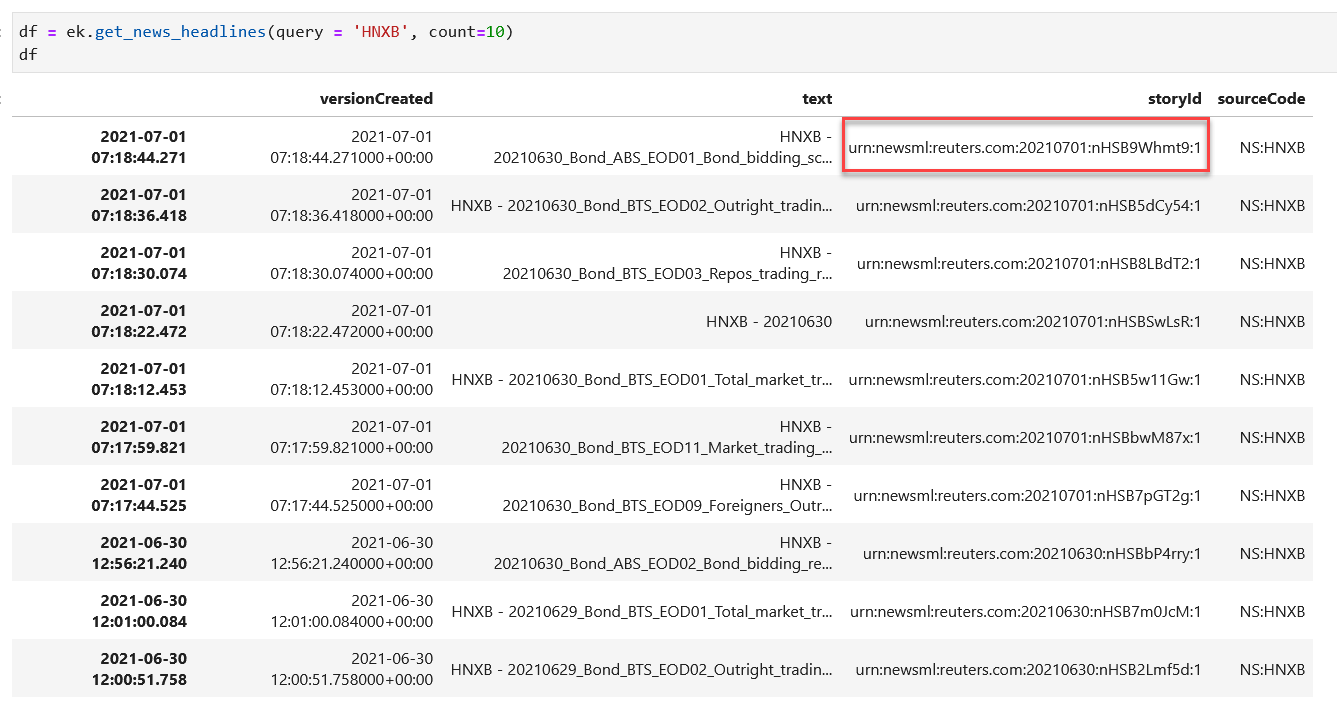

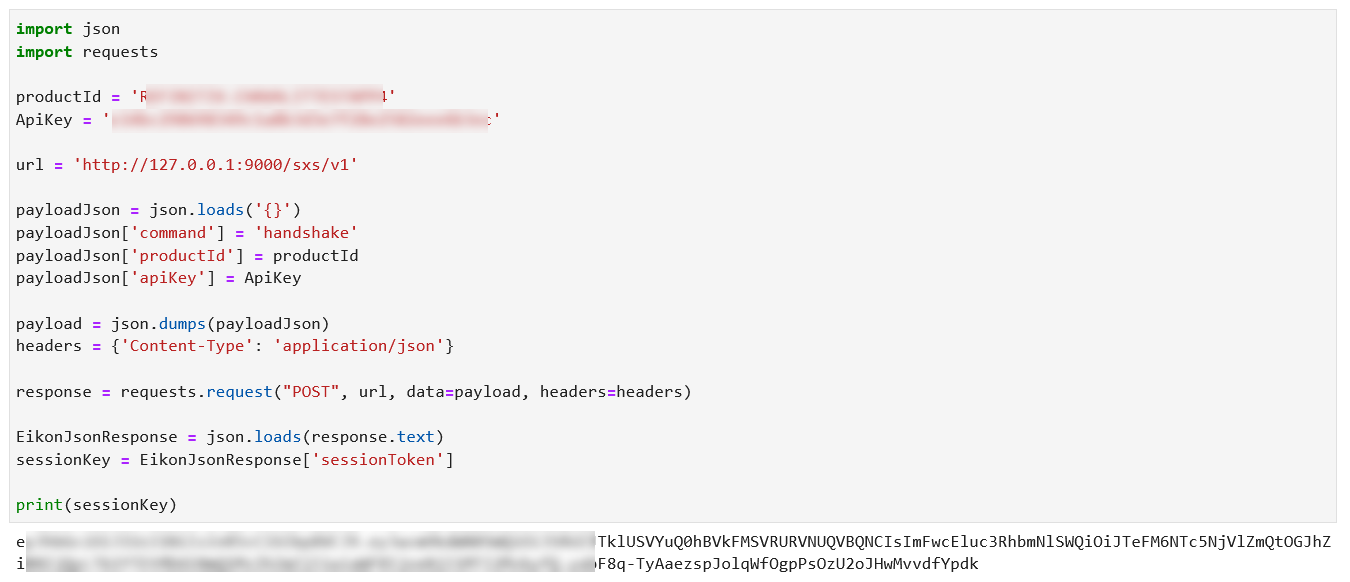
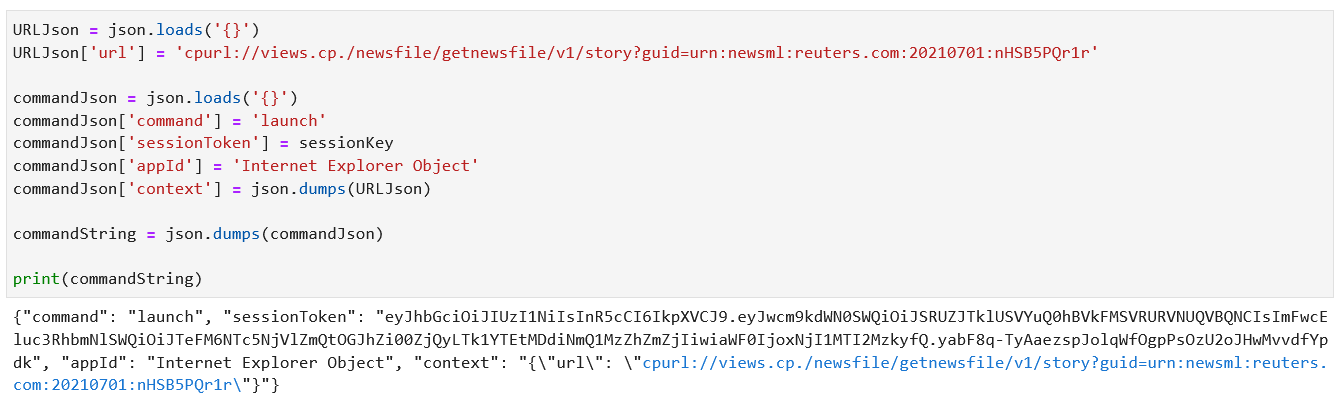
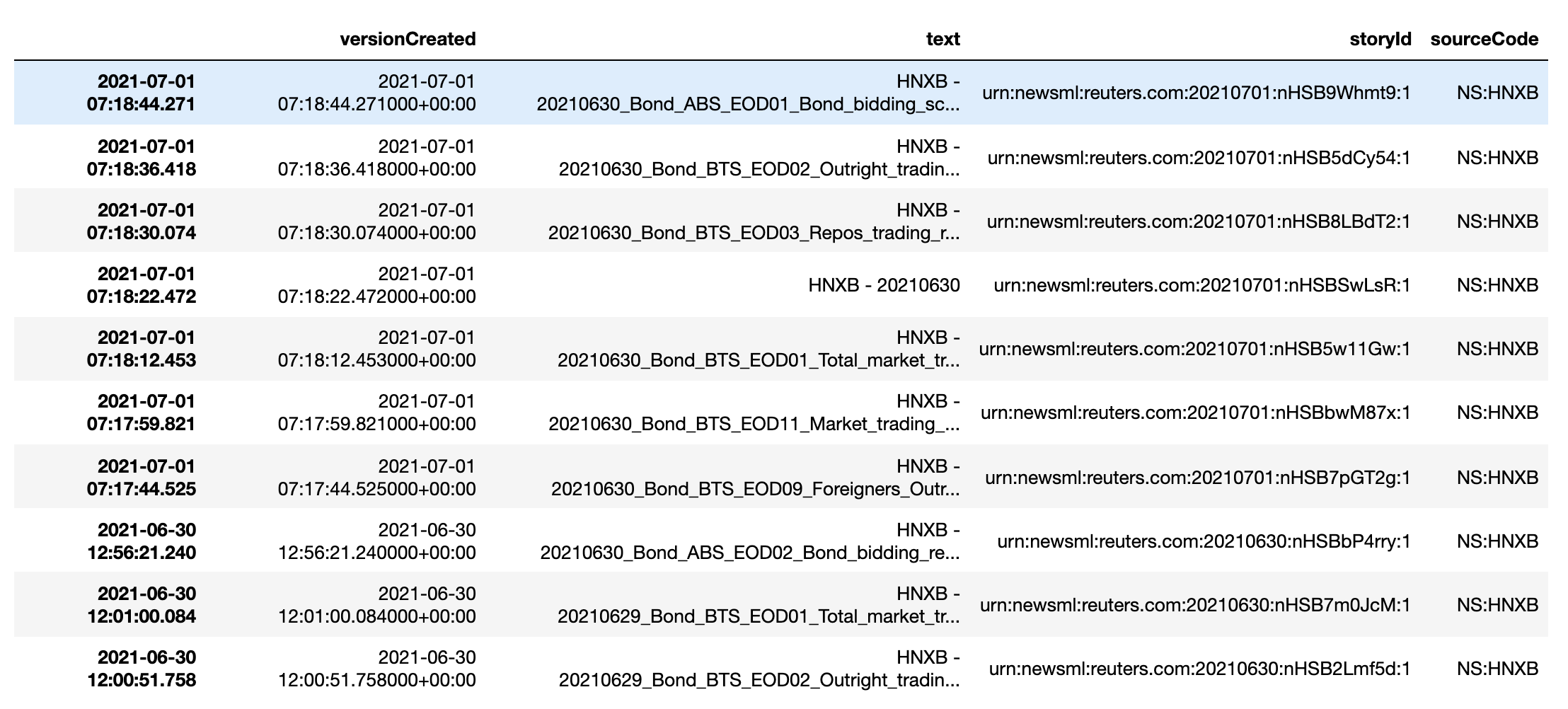

{kind=link}
{kind=link}