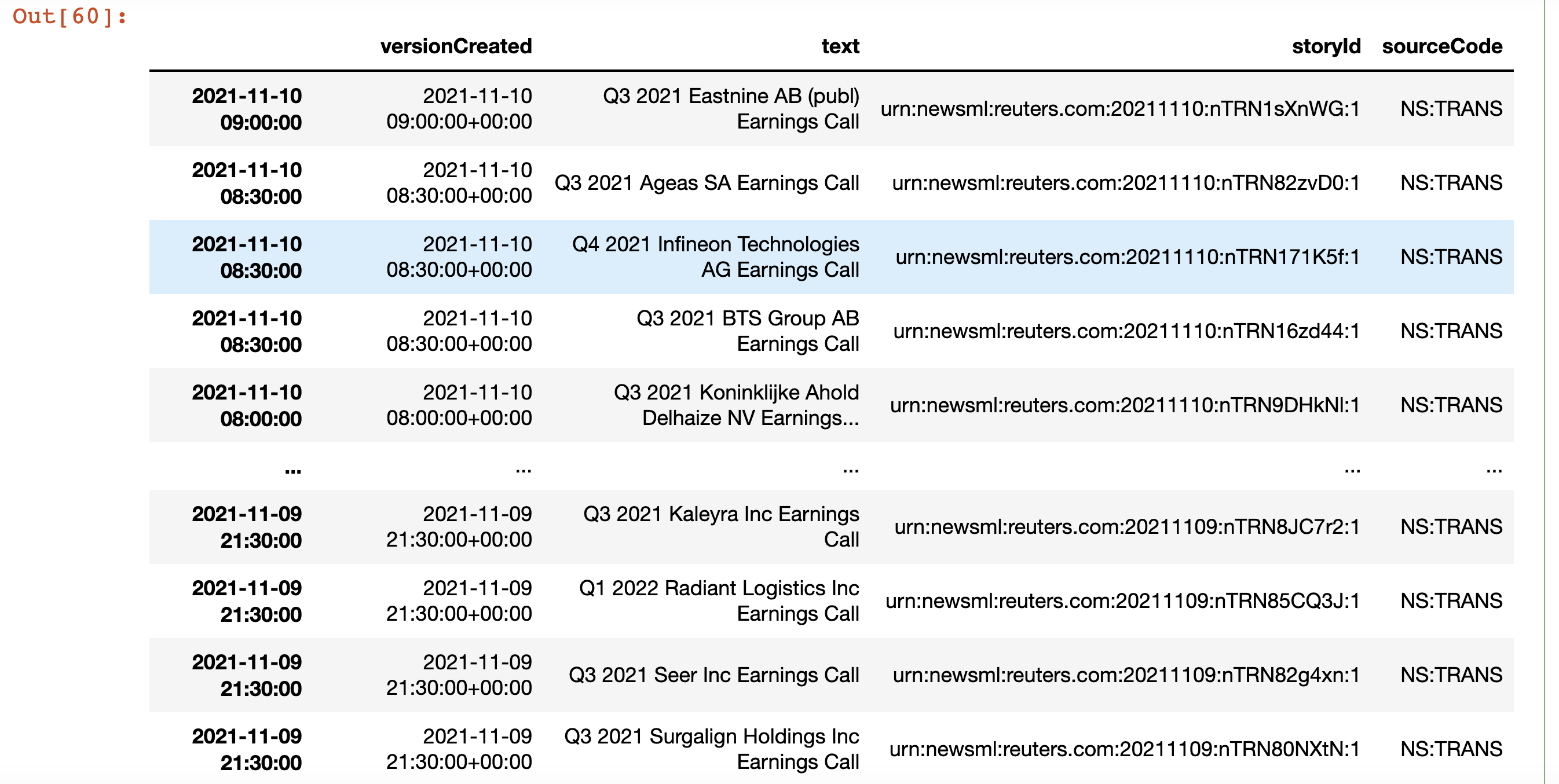
Is there any way to retrieve mp3, presentation and transcripts of corporate analyst meetings via the eikon api?
Regarding the transcripts, I read that it seems not to be possible to get them but I was thinking that there should be a way to get the list of events via news searching (as opposed to the events app). From them on it simple.
Anyway, I could use some help in retrieving the presentations and mp3s
thanks