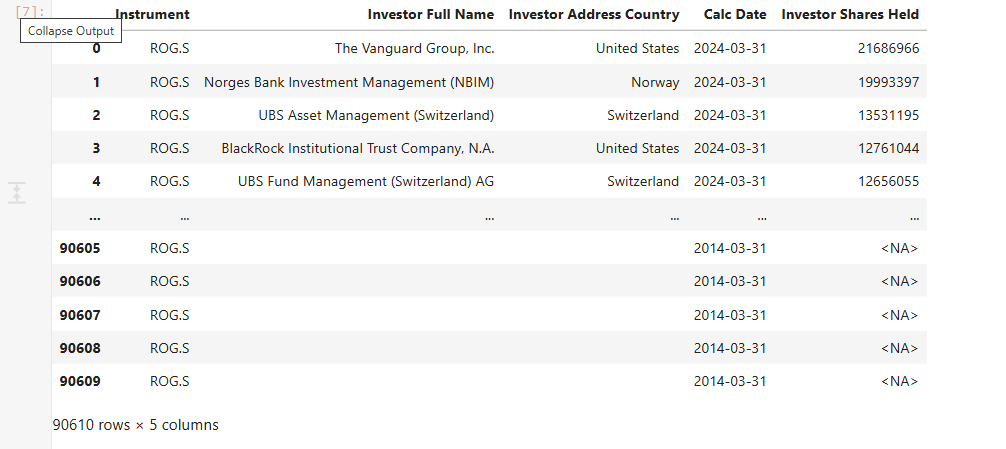
I am looking to get the portfolio investment equity shareholder info for ROG.S at a quarterly frequency from 2014Q1 to 2024Q2. Ideally, it would be a CSV file with Firm,InvestorName,InvestorCountry,YearQuarter,InvestorShare. Firm would show ROG.S, InvestorName and InvestorCountry would be strings and YearQuarter would be in format YYYYQQ.
In previous queries for other RICs I used these fields to retrieve the information: TR.InvestorFullName, TR.InvAddrCountry, TR.SharesHeld.calcdate and TR.SharesHeld. For some reason, I cannot find this info for ROG.S
Script:
all_rows = [] # will hold every RIC’s long dataframe
skipped_info = [] # keeps track of problems so you can inspect later
for i, row in df_firm_list.iterrows():
ric = row["RIC_2"]
start_date = pd.to_datetime(row["Start_date"]).strftime("%Y-%m-%d")
end_date = pd.to_datetime(row["End_date"]).strftime("%Y-%m-%d")
print(f"{i+1:3}/{len(df_firm_list)} → {ric} ({start_date}‒{end_date})")
------------------------Fetch data from Refinitiv------------------------
try:
df_raw = rd.get_data(
universe = [ric],
fields = ["TR.InvestorFullName",
"TR.InvAddrCountry",
"TR.SharesHeld.calcdate",
"TR.SharesHeld"],
parameters = {
"SDate": start_date,
"EDate": end_date,
"Frq": "Q", # quarterly
"Date": "calcdate"
}
)
except Exception as ex:
print(f" Error: {ex}")
skipped_info.append({"RIC": ric, "Reason": f"Exception: {ex}"})
continue
if df_raw is None or df_raw.empty:
print(" No data returned")
skipped_info.append({"RIC": ric, "Reason": "No data returned"})
continue
------------------------Clean / reshape------------------------
if len(df_raw.columns) != 5: # safety check – Refinitiv should give exactly five columns
print(f" Unexpected column layout ({len(df_raw.columns)} columns), skipping")
skipped_info.append({"RIC": ric, "Reason": f"Unexpected columns: {df_raw.columns.tolist()}"})
continue
df_raw.columns = ["Instrument", "InvestorName", "InvestorCountry",
"InvestorDate", "InvestorShare"]
Convert calcdate to datetime and build YearQuarter label
df_raw["InvestorDate"] = pd.to_datetime(df_raw["InvestorDate"], errors="coerce")
df_raw["YearQuarter"] = (
df_raw["InvestorDate"].dt.year.astype(str)
- "Q"
- df_raw["InvestorDate"].dt.quarter.astype(str)
)
Keep only the columns we need + add Firm
df_tidy = df_raw[["InvestorName", "InvestorCountry", "YearQuarter", "InvestorShare"]].copy()
df_tidy.insert(0, "Firm", ric)
Remove duplicates that sometimes appear in the feed
df_tidy = df_tidy.drop_duplicates(
subset=["Firm", "InvestorName", "InvestorCountry", "YearQuarter"],
keep="first"
)
all_rows.append(df_tidy)
------------------------------------------------------------------5. Concatenate and save to CSV------------------------------------------------------------------
if all_rows:
df_long = pd.concat(all_rows, ignore_index=True)
df_long.to_csv(output_csv, index=False)
print(f"Saved {len(df_long):,} rows to
{output_csv}")
else:
print("No data retrieved for any RIC – nothing written")
------------------------------------------------------------------6. Write skipped RICs log (if any)------------------------------------------------------------------
if skipped_info:
pd.DataFrame(skipped_info).to_csv(skipped_csv, index=False)
print(f"Logged {len(skipped_info)} skipped RICs to {skipped_csv}")
else:
print(" Every RIC returned data")
print("
Script finished.")
This is part of the code of our query. But if it's possible to just get the output for ROG.S that would be much better that working on the query itself.