Hello, I am using the lseg data library for async data dumping for 60,000 RICs and I have encountered a problem that sometimes the response for some RICs does not return data.
I checked the availability of dumped indicators for specific RICs using workspace. These indicators are present, but when I request them to the API, they are not returned to me.
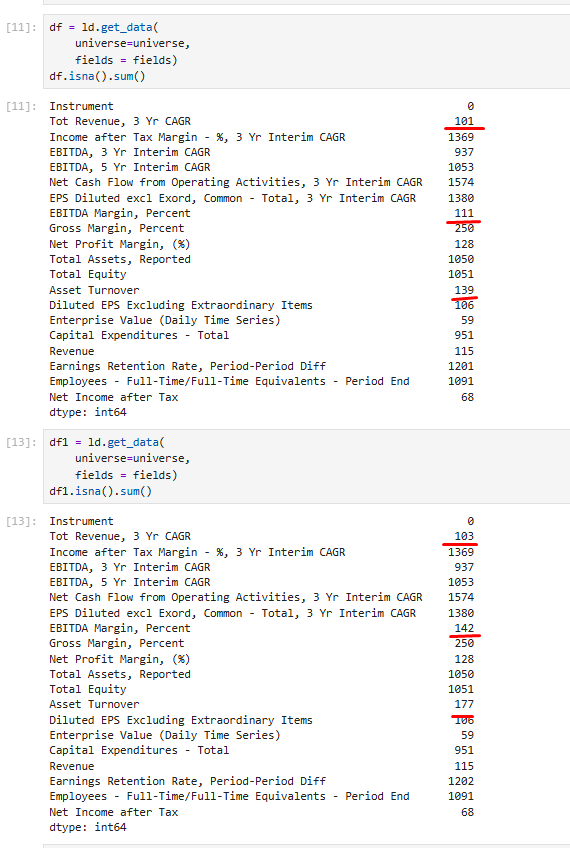
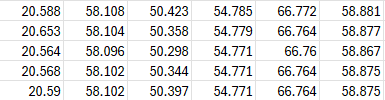
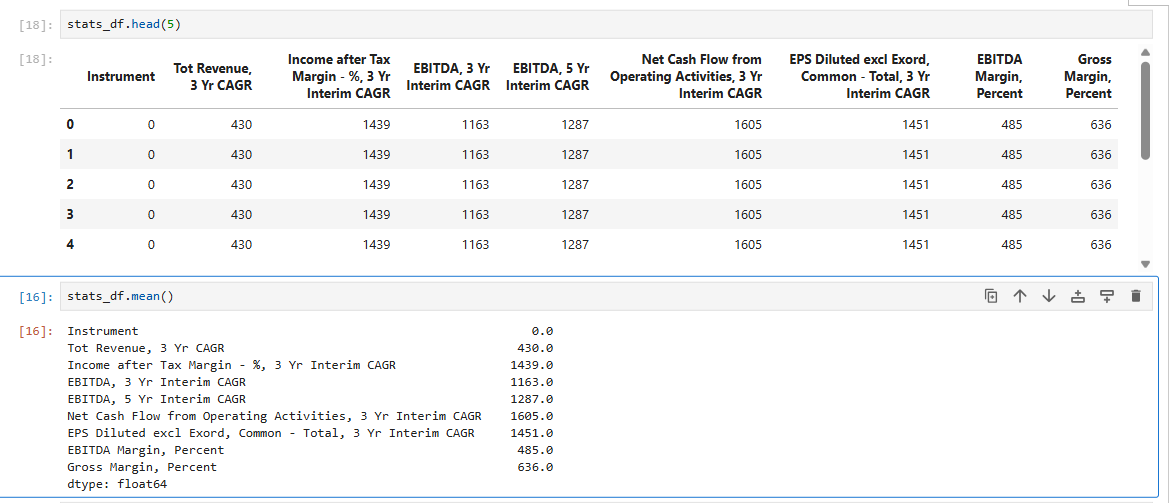
I have made several identical dumps and received a different number of missing values in the columns.
df.isna().mean() * 100

Accordingly, each time I did not receive data for some RICs. Here are the differences in data between dumps 1 and 3.
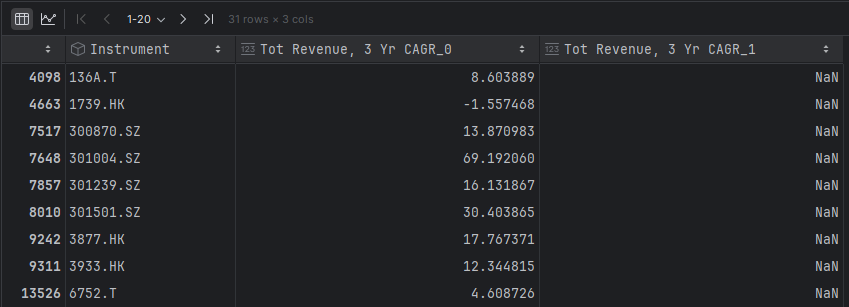
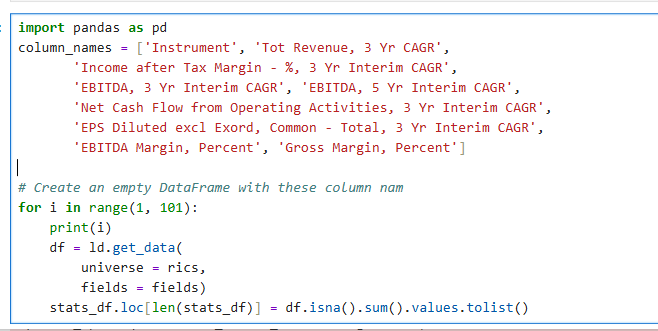
I am using dumping for 2500 RICs and an async function.
Code:
FIELDS = ['TR.TotRevenue3YrCAGR',
'TR.F.IncAftTaxMargPct3YrIntmCAGR',
'TR.EBITDA3YrInterimCAGR',
'TR.F.EBITDA5YrIntmCAGR',
'TR.F.NetCFOp3YrIntmCAGR',
'TR.F.EPSDilExclExOrdComTot3YrIntmCAGR',
'TR.EBITDAMarginPercent(Period=LTM)',
'TR.GrossMargin(Period=LTM)',
'TR.NetProfitMargin(Period=LTM)',
'TR.TotalAssetsReported(Period=FQ0)',
'TR.TotalEquity(Period=FQ0)',
'TR.AssetTurnover(Period=LTM)',
'TR.DilutedEpsExclExtra(Period=LTM)',
'TR.EV',
'TR.F.CAPEXTot(Period=LTM)',
'TR.Revenue(Period=LTM)',
'TR.EarningsRetentionRatePeriodToPeriodDiff',
'TR.F.EmpFTEEquivPrdEnd',
'TR.F.NetIncAfterTax(Period=LTM)']
PARAMS = {'Curn': 'USD', 'CH': 'Fd'}
response = await fundamental_and_reference.Definition(
universe=rics_batch,
fields=FIELDS,
parameters=PARAMS
).get_data_async()
Attached the log file for 1 and 3 unloading to the letter.
Can you recommend a solution to this problem?