Greetings,
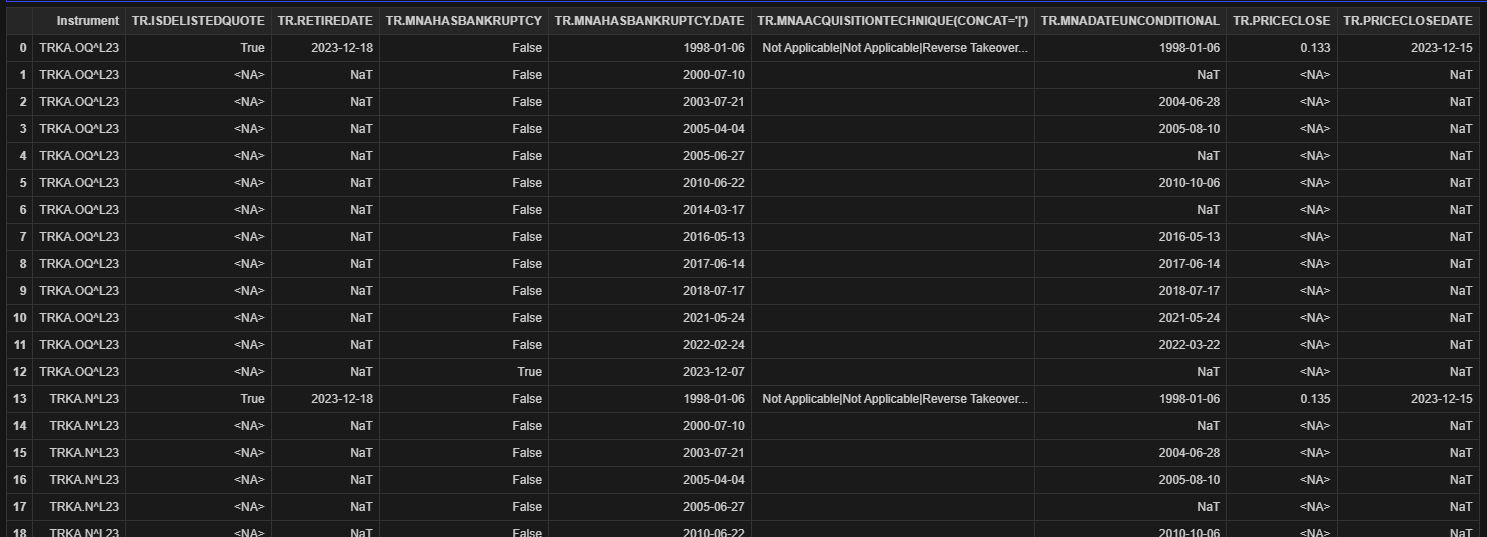
I am currently involved in a project aimed at retrieving the closing price for companies that have been delisted due to bankruptcy, specifically the day following their bankruptcy announcement. The primary methodology I employ involves checking whether 'TR.MnAHasBankruptcy' is true. If this condition is met, we proceed to use 'TR.MnAHasBankruptcy.date' to extract the closing price on the subsequent day, utilizing "TR.PriceCloseDate".
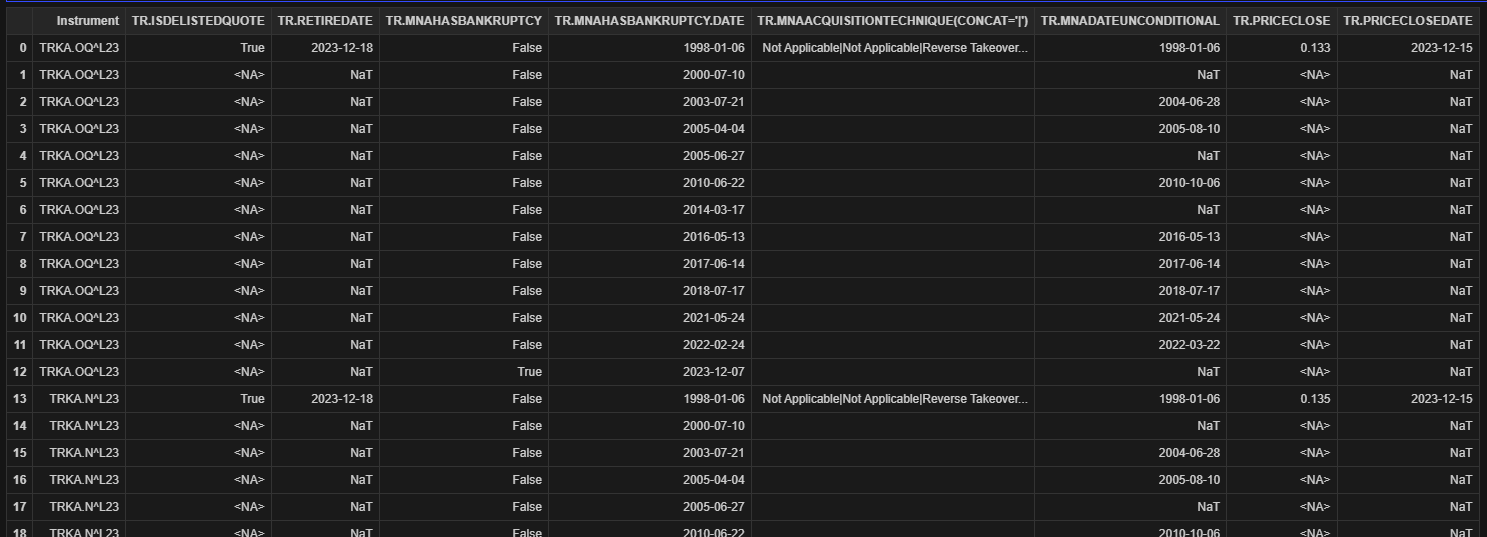
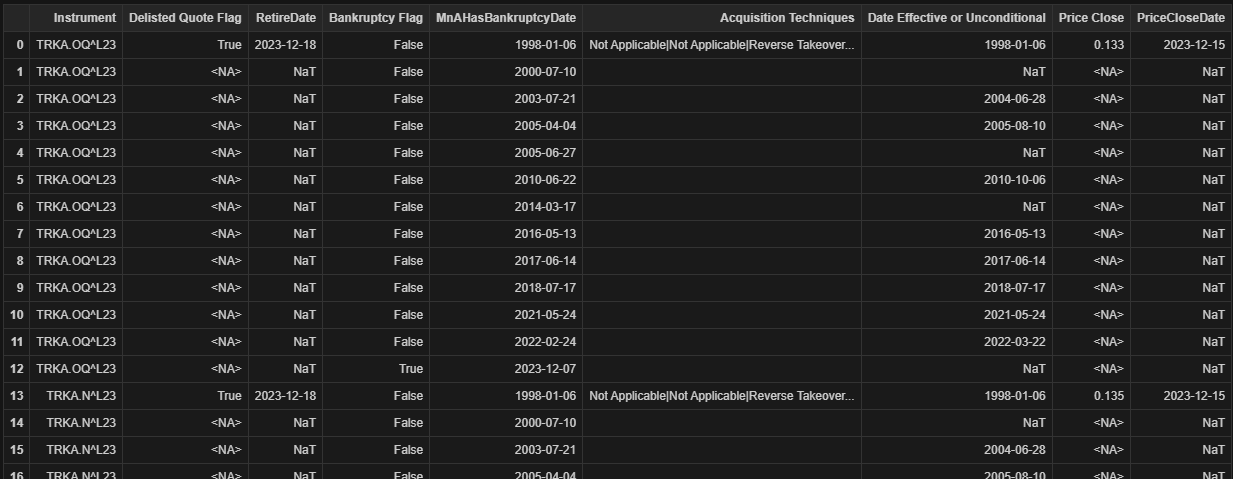
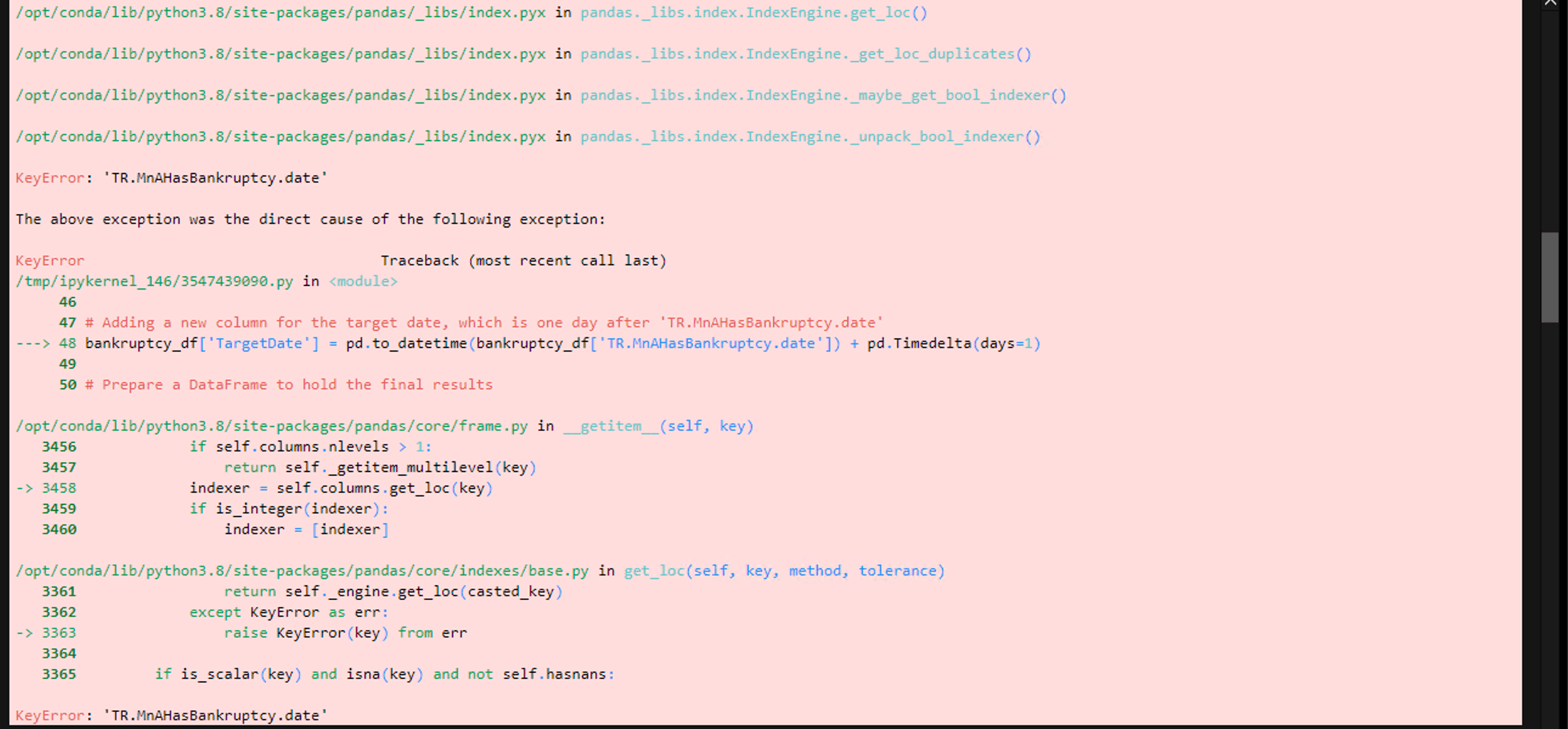
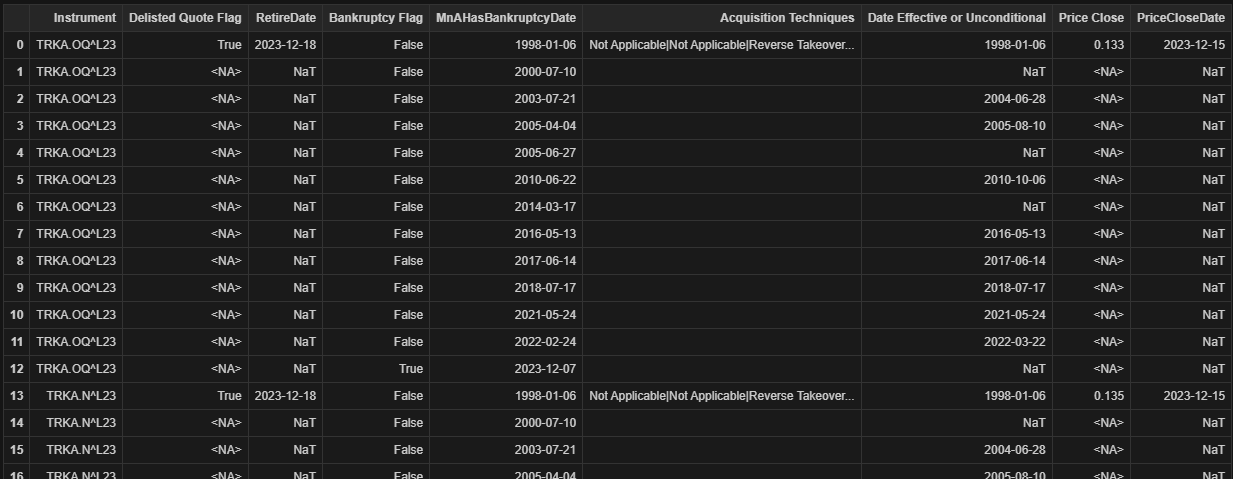
I have encountered a challenge in executing the code intended for this purpose. For reference, the dataframe columns available for extraction are as follows: Index(['Instrument', 'Delisted Quote Flag', 'RetireDate', 'Bankruptcy Flag', 'Date', 'Acquisition Techniques', 'Date Effective or Unconditional', 'Price Close', 'Date'], dtype='object'). It is noteworthy that both 'TR.MnAHasBankruptcy.date' and "TR.PriceCloseDate" correspond to the same field name "Date".
I am seeking a solution to address this ambiguity between field names. What strategies could potentially resolve this issue?
Thank you!
import refinitiv.data as rd
import pandas as pd
rd.open_session()
results = rd.discovery.search(
view=rd.discovery.Views.EQUITY_QUOTES,
top=500,
filter="(IssuerOAPermID eq '4295899979' and RCSAssetCategoryLeaf eq 'Ordinary Share')",
select="RIC, DTSubjectName, RCSAssetCategoryLeaf, ExchangeName, ExchangeCountry"
)
df = results
substrings = ['.OQ', '.O', '.N', '.A']
def is_valid_ric(ric):
for ending in substrings:
if ending in ric:
pos = ric.find(ending)
if len(ric) == pos + len(ending) or (len(ric) > pos + len(ending) and ric[pos + len(ending)] == '^'):
return True
return False
filtered_df = df[df['RIC'].apply(is_valid_ric)]
rics = filtered_df['RIC'].tolist()
df = rd.get_data(
universe=rics,
fields=[
'TR.IsDelistedQuote',
'DELIST_DAT',
'TR.RetireDate',
'TR.MnAHasBankruptcy',
'TR.MnAHasBankruptcy.date',
"TR.MnAAcquisitionTechnique(Concat='|')",
'TR.MnADateUnconditional',
"TR.PriceClose",
"TR.PriceCloseDate",
],
parameters={}
)
# Filtering DataFrame where 'TR.MnAHasBankruptcy' is True
bankruptcy_df = df[df['Bankruptcy Flag'] == True].copy()
# Adding a new column for the target date, which is one day after 'TR.MnAHasBankruptcy.date'
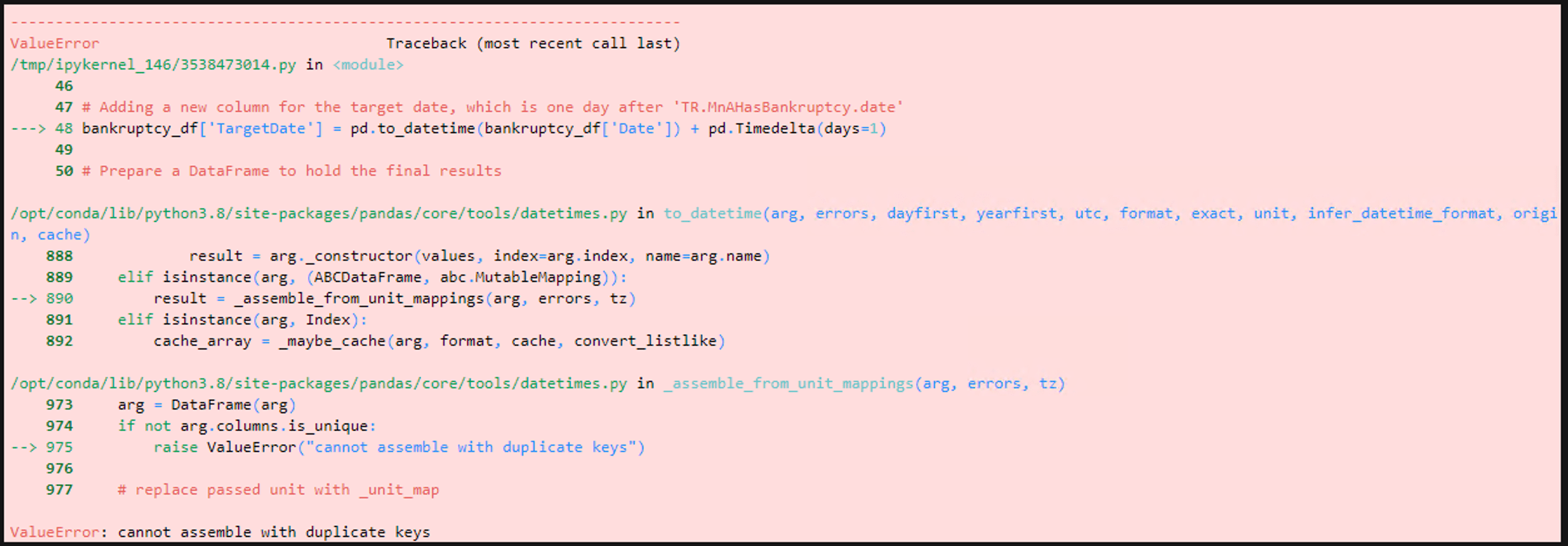
bankruptcy_df['TargetDate'] = pd.to_datetime(bankruptcy_df['TR.MnAHasBankruptcy.date']) + pd.Timedelta(days=1)
# Prepare a DataFrame to hold the final results
final_columns = ['RIC', 'TR.MnAHasBankruptcy.date', 'TargetDate', 'Price Close']
final_df = pd.DataFrame(columns=final_columns)
# Iterate through the bankruptcy DataFrame
for index, row in bankruptcy_df.iterrows():
target_date = row['TargetDate']
ric = row['RIC']
# Attempt to find the 'TR.PriceClose' where 'TR.PriceCloseDate' matches 'TargetDate'
price_close_row = df[(df['RIC'] == ric) & (pd.to_datetime(df['TR.PriceCloseDate']) == target_date)]
if not price_close_row.empty:
price_close = price_close_row.iloc[0]['Price Close']
final_df = final_df.append({
'RIC': ric,
'TR.MnAHasBankruptcy.date': row['TR.MnAHasBankruptcy.date'],
'TargetDate': target_date,
'Price Close': price_close
}, ignore_index=True)
else:
# Handle the case where no matching 'TR.PriceClose' is found
final_df = final_df.append({
'RIC': ric,
'TR.MnAHasBankruptcy.date': row['TR.MnAHasBankruptcy.date'],
'TargetDate': target_date,
'Price Close': "<NA>"
}, ignore_index=True)
print(final_df)
final_df.to_csv("./bankruptcy_price_close.csv")
rd.close_session()



{kind=link}
{kind=link}