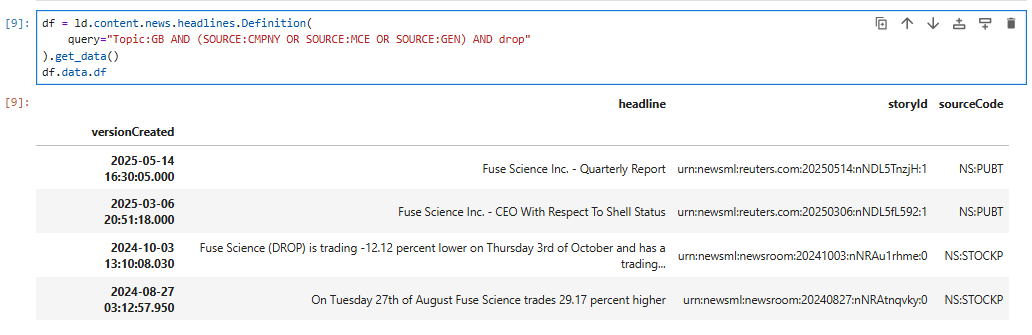
Hi
I currently have the following code that is fetching specific new articles using Python API. However I am not sure how to add the story text to the output. I currently have the Headline, StoryId, and Link to the article.
Code:
df = ek.get_news_headlines(
'Topic:GB AND (SOURCE:CMPNY OR SOURCE:MCE OR SOURCE:GEN)',
date_from='2025-07-23',
date_to='2025-07-30')
df
df['Links']=""
for idx, story in enumerate(df['storyId']):
soup = BeautifulSoup(ek.get_news_story(story))
links=[]
for a in soup.find_all('a', href=True):
links.append(a['href'])
df['Links'][idx] = links
df
I've added the output as a picture.
Any help would be great. Thanks.