I have question about the LSEG Workspace value chains data (VCHAIN). For some time we've been pulling the VCHAIN data via the Refinitiv API.
This works like a charm for the following fields: TR.SCRelationship', 'TR.SCRelationship.ScorgIDOut', 'TR.SCRelationship.instrument', 'TR.SCRelationshipConfidenceScore', 'TR.SCRelationshipFreshnessScore', 'TR.SCRelationshipUpdateDate'.
We use this Python code:
value_chains = dl.get_data(
universe=inputList,
fields=['TR.SCRelationship', 'TR.SCRelationship.ScorgIDOut',
'TR.SCRelationship.instrument', 'TR.SCRelationshipConfidenceScore', 'TR.SCRelationshipFreshnessScore','TR.SCRelationshipUpdateDate']
)
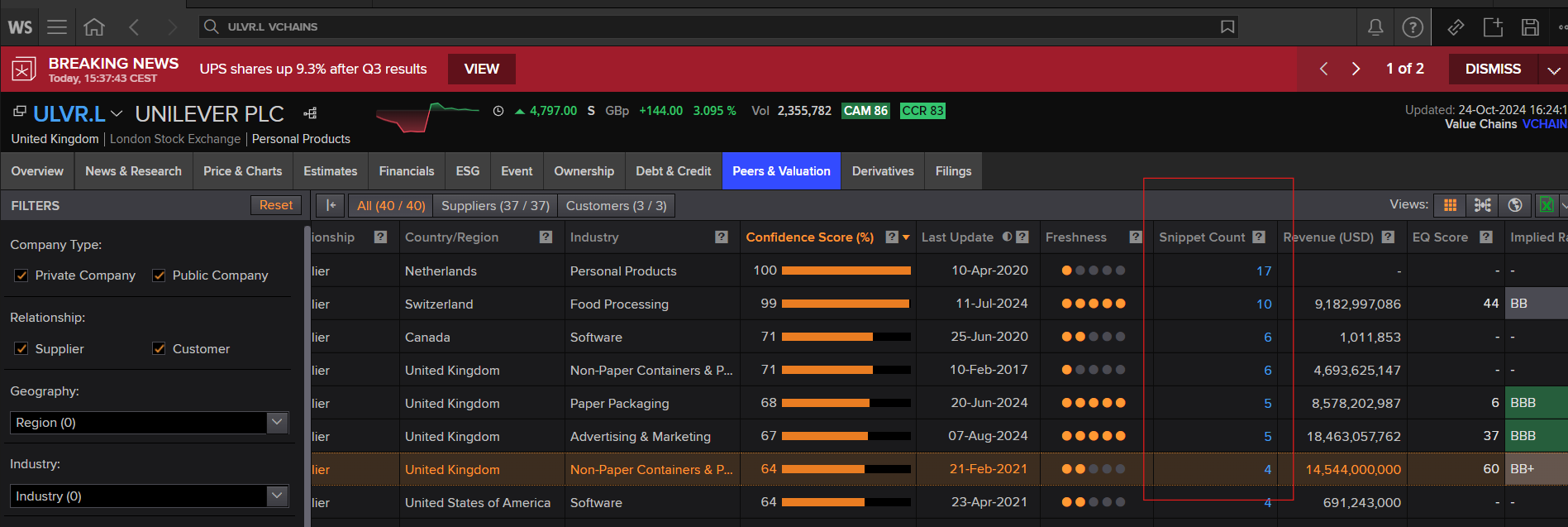
However, we also want to pull the data of the news snippets (not the snippets themselves, only the dates) available in the Workspace. See screenshots below for how to find them in the Workspace. We'd like to do this via the API because we work with a big dataset of companies, but we cannot find a field code to do so. Is this possible via the API?
Best regards, Maarten Gubbels
Data Librarian for the Nijmegen School of Management, Radboud University Nijmegen (Netherlands)
snippet date, the fiels we'd like to pull
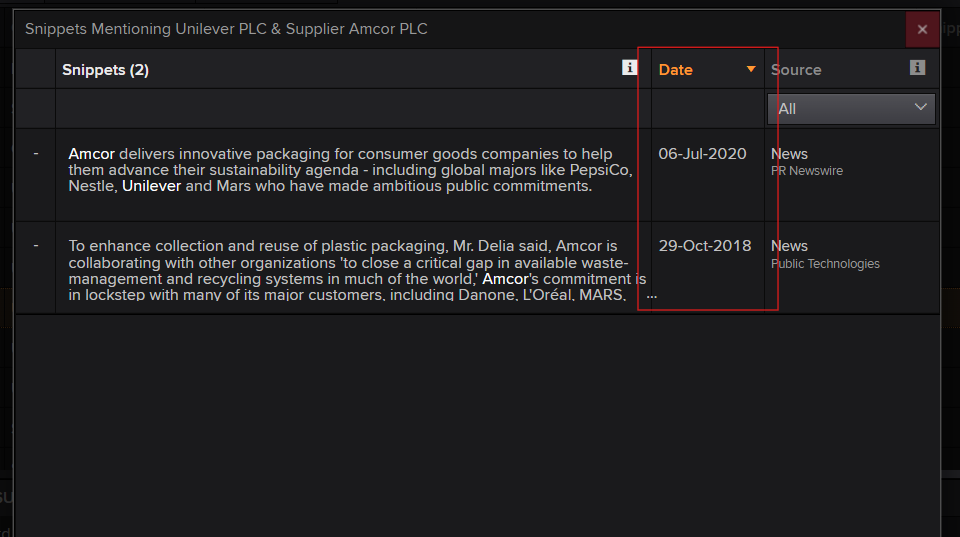
Where to find this date in the LSEG Workspace (VCHAIN app):