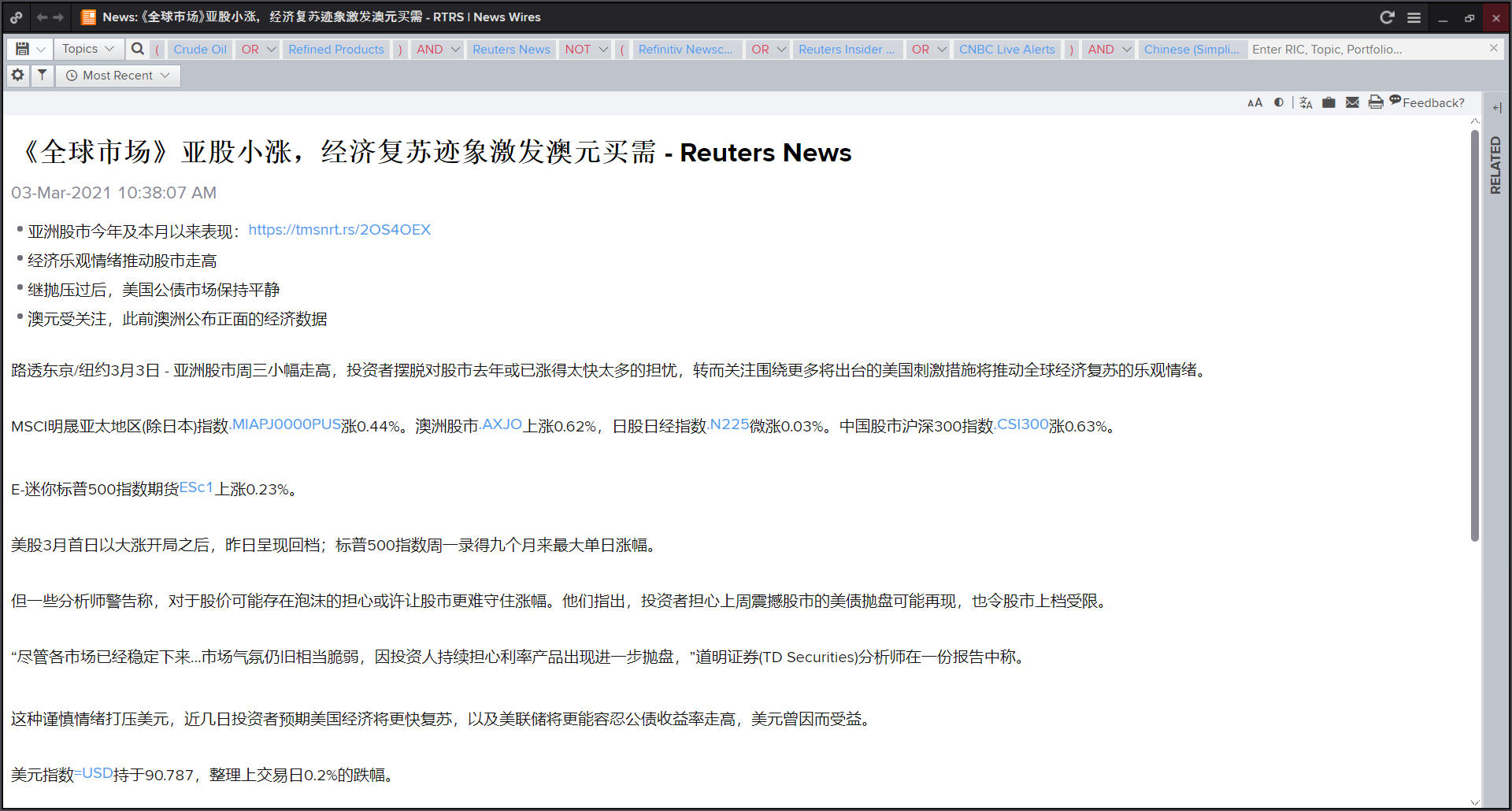
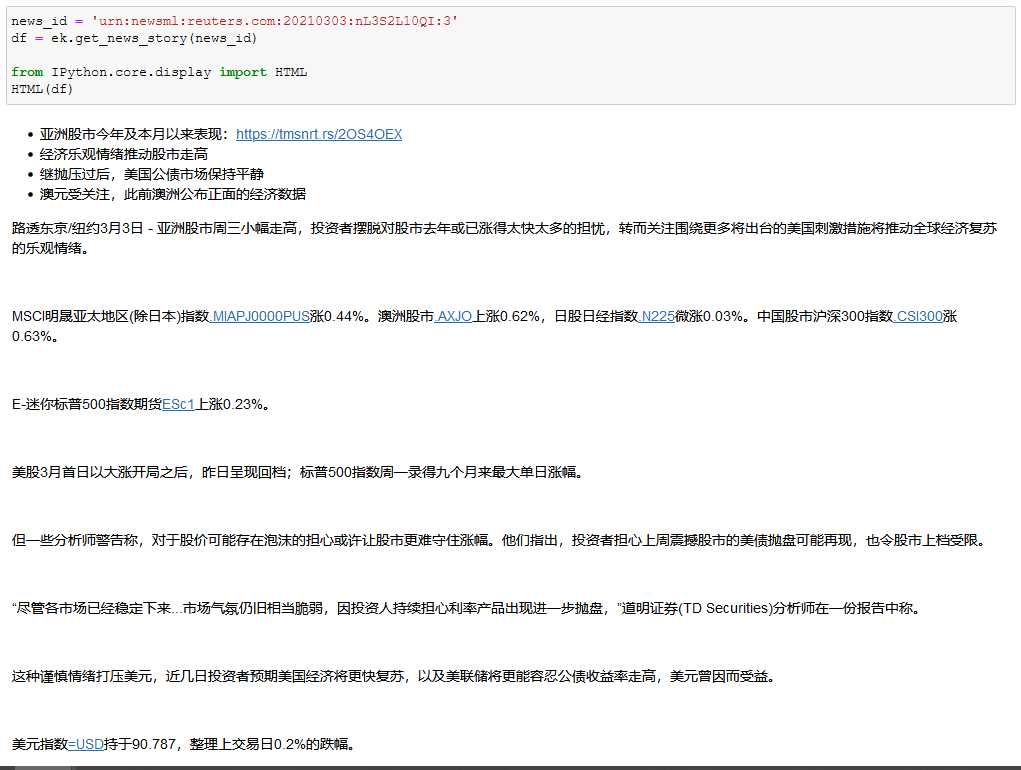
Hello,
I tried to download daily oil Chinese news to html file.The code is as follows:
#OIL新闻下载
def download_headlines(query,S_date,E_date):
headlines = pd.DataFrame()
try:
while E_date > S_date:
headline = ek.get_news_headlines(query,date_to=E_date,count=100)
headlines = headlines.append(headline)
t = headline.iat[len(headline)-1,0]
E_date = t.strftime("%Y-%m-%dT%H:%M:%S.%f")
except:
print('出错了...')
finally:
headlines = headlines.drop_duplicates()
headlines = headlines.drop(headlines[headlines.versionCreated < S_date].index)
print('下载新闻标题总数:%d' % len(headlines))
return headlines
query_oil = '( Topic:CRU OR Topic:PROD ) AND Source:RTRS NOT ( Product:RITV OR Product:RCNBC OR Product:LCNBC ) in LZS'
End_date = datetime.datetime.now()
Start_date = End_date - timedelta(days=1)
headlines_oil = download_headlines(query_oil,str(Start_date),str(End_date))
headlines = headlines_oil
#下载全部新闻内容
headlines['story'] = [ek.get_news_story(each) for each in headlines['storyId'].tolist()]
#正则化
import re
headlines['story'] = headlines['story'].apply(lambda x: re.sub(r"</p>|<p>|</div>",'',x)) # 删除段落符
headlines['story'] = headlines['story'].apply(lambda x: re.sub(r"<br/><br/>",'<br/>',x)) # 删除段落之间的过多空行
headlines['story'] = headlines['story'].apply(lambda x: re.sub(r"<br/>",'<br/><br/>',x)) # 使段落之间强制空一行
headlines['story'] = headlines['story'].apply(lambda x: re.sub(r"[(|(]完(.*?)$",'【完】',x)) # 修改 (完) -> 【完】
headlines['story'] = headlines['story'].apply(lambda x: re.sub(r"[(|(]c(.*?)Copyright(.*?)$",'',x)) # 删除“(c) Copyright”之后的内容
headlines['story'] = headlines['story'].apply(lambda x: re.sub(r"[(|(]([编译|发稿|整理|审校|Reporting|Editting])(.*?)$",'',x)) # 删除“(编译|发稿|Reporting”之后的内容
#转化为html文件
os.chdir(r'D:/TASK/Daily')
f = open('daily.html','w',encoding='utf-8') # 创建 news_archive.html
f = open('daily.html','a',encoding='utf-8') # 设置追加写入模式
f.writelines('目录<hr>')
table_of_content=headlines.text.tolist()
for each in table_of_content:
f.writelines(each + '<br/>')
f.writelines('<hr><br/>')
for i in range(len(headlines)):
f.writelines('<font color="#FF0000">'+ headlines.iat[i,1]+'</font><br/><br/>') #写入新闻标题,红色,空一行
f.write(headlines.iat[i,4]+'<hr><br/>') #写入新闻全文,文后加横线分隔
f.close()
However,though I've input encoding = 'utf-8' when writing html file,the output are still garbled words.Can you help me?

Thank you