I am getting below error in pythong when using RTH REST Api:
Quota Message: INFO: Tick History Futures Quota Count Before Extraction: 0; Instruments Approved for Extraction: 0; Tick History Futures Quota Count After Extraction: 0, 100% of Limit; Tick History Futures Quota Limit: 0
Quota Message: ERROR: The RIC 'STXE' in the request would exceed your quota limits. Adjust your input list to continue.
Quota Message: WARNING: Tick History Futures Quota has been reached or exceeded
I have checked from the GUI and it says below:
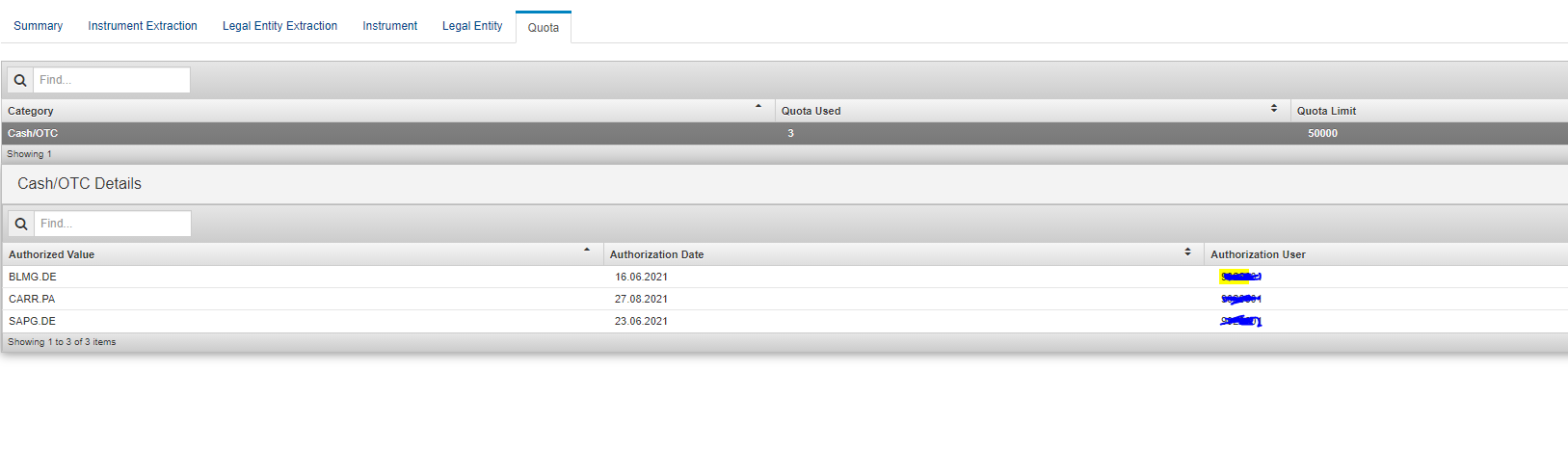
What should i do in this case ? Do i need to change anything in Python code or need to contact ny Refinitiv Account manager ?
Below is my Python Code:
# coding: utf-8
# In[2]:
# ====================================================================================
# On Demand request demo code, using the following steps:
# - Authentication token request
# - On Demand extraction request
# - Extraction status polling request
# Extraction notes retrieval
# - Data retrieval and save to disk (the data file is gzipped)
# Includes AWS download capability
# ====================================================================================
# Set these parameters before running the code:
filePath = "P:\\ODI_Projects\\temp\\" # Location to save downloaded files
fileNameRoot = "Python_Test" # Root of the name for the downloaded files
useAws = True
# Set the last parameter above to:
# False to download from TRTH servers
# True to download from Amazon Web Services cloud (recommended, it is faster)
# Imports:
import requests
import json
import shutil
import time
import gzip
import os
# ====================================================================================
# Step 1: token request
#proxy setting
os.environ["HTTPS_PROXY"] = "http://proxy:8080"
reqStart = "https://selectapi.datascope.refinitiv.com/RestApi/v1"
requestUrl = reqStart + "/Authentication/RequestToken"
requestHeaders = {
"Prefer": "respond-async",
"Content-Type": "application/json"
}
requestBody = {
"Credentials": {
"Username": myUsername,
"Password": myPassword
}
}
r1 = requests.post(requestUrl, json=requestBody, headers=requestHeaders)
if r1.status_code == 200:
jsonResponse = json.loads(r1.text.encode('ascii', 'ignore'))
token = jsonResponse["value"]
print('Authentication token (valid 24 hours):')
print(token)
else:
print('Replace myUserName and myPassword with valid credentials, then repeat the request')
# In[7]:
# Step 2: send an on demand extraction request using the received token
requestUrl = reqStart + '/Extractions/ExtractRaw'
requestHeaders = {
"Prefer": "respond-async",
"Content-Type": "application/json",
"Authorization": "token " + token
}
requestBody = {
"ExtractionRequest": {
"@odata.type": "#DataScope.Select.Api.Extractions.ExtractionRequests.TickHistoryRawExtractionRequest",
"IdentifierList": {
"@odata.type": "#DataScope.Select.Api.Extractions.ExtractionRequests.InstrumentIdentifierList",
"InstrumentIdentifiers": [{
"Identifier": "STXEc1",
"IdentifierType": "Ric"
}]
},
"Condition": {
"MessageTimeStampIn": "GmtUtc",
"ReportDateRangeType": "Range",
"QueryStartDate": "2021-08-20T12:00:00.000Z",
"QueryEndDate": "2021-08-20T12:10:00.000Z",
"Fids": "22,30,25,31,14265,1021",
"ExtractBy": "Ric",
"SortBy": "SingleByRic",
"DomainCode": "MarketPrice",
"DisplaySourceRIC": "true"
}
}
}
r2 = requests.post(requestUrl, json=requestBody, headers=requestHeaders)
r3 = r2
# Display the HTTP status of the response
# Initial response status (after approximately 30 seconds wait) is usually 202
status_code = r2.status_code
print("HTTP status of the response: " + str(status_code))
# In[8]:
# Step 3: if required, poll the status of the request using the received location URL.
# Once the request has completed, retrieve the jobId and extraction notes.
# If status is 202, display the location url we received, and will use to poll the status of the extraction request:
if status_code == 202:
requestUrl = r2.headers["location"]
print('Extraction is not complete, we shall poll the location URL:')
print(str(requestUrl))
requestHeaders = {
"Prefer": "respond-async",
"Content-Type": "application/json",
"Authorization": "token " + token
}
# As long as the status of the request is 202, the extraction is not finished;
# we must wait, and poll the status until it is no longer 202:
while (status_code == 202):
print('As we received a 202, we wait 30 seconds, then poll again (until we receive a 200)')
time.sleep(30)
r3 = requests.get(requestUrl, headers=requestHeaders)
status_code = r3.status_code
print('HTTP status of the response: ' + str(status_code))
# When the status of the request is 200 the extraction is complete;
# we retrieve and display the jobId and the extraction notes (it is recommended to analyse their content)):
if status_code == 200:
r3Json = json.loads(r3.text.encode('ascii', 'ignore'))
jobId = r3Json["JobId"]
print('\njobId: ' + jobId + '\n')
notes = r3Json["Notes"]
print('Extraction notes:\n' + notes[0])
# If instead of a status 200 we receive a different status, there was an error:
if status_code != 200:
print('An error occured. Try to run this cell again. If it fails, re-run the previous cell.\n')
# In[9]:
# Step 4: get the extraction results, using the received jobId.
# Decompress the data and display it on screen.
# Skip this step if you asked for a large data set, and go directly to step 5 !
# We also save the data to disk; but note that if you use AWS it will be saved as a GZIP,
# otherwise it will be saved as a CSV !
# This discrepancy occurs because we allow automatic decompression to happen when retrieving
# from TRTH, so we end up saving the decompressed contents.
# IMPORTANT NOTE:
# The code in this step is only for demo, to display some data on screen.
# Avoid using this code in production, it will fail for large data sets !
# See step 5 for production code.
# Display data:
# ZF print ('Decompressed data:\n' + uncompressedData)
# Note: variable uncompressedData stores all the data.
# This is not a good practice, that can lead to issues with large data sets.
# We only use it here as a convenience for the demo, to keep the code very simple.
# In[10]:
# Step 5: get the extraction results, using the received jobId.
# We also save the compressed data to disk, as a GZIP.
# We only display a few lines of the data.
# IMPORTANT NOTE:
# This code is much better than that of step 4; it should not fail even with large data sets.
# If you need to manipulate the data, read and decompress the file, instead of decompressing
# data from the server on the fly.
# This is the recommended way to proceed, to avoid data loss issues.
# For more information, see the related document:
# Advisory: avoid incomplete output - decompress then download
requestUrl = requestUrl = reqStart + "/Extractions/RawExtractionResults" + "('" + jobId + "')" + "/$value"
# AWS requires an additional header: X-Direct-Download
if useAws:
requestHeaders = {
"Prefer": "respond-async",
"Content-Type": "text/plain",
"Accept-Encoding": "gzip",
"X-Direct-Download": "true",
"Authorization": "token " + token
}
else:
requestHeaders = {
"Prefer": "respond-async",
"Content-Type": "text/plain",
"Accept-Encoding": "gzip",
"Authorization": "token " + token
}
r5 = requests.get(requestUrl, headers=requestHeaders, stream=True)
# Ensure we do not automatically decompress the data on the fly:
r5.raw.decode_content = False
if useAws:
print('Content response headers (AWS server): type: ' + r5.headers["Content-Type"] + '\n')
# AWS does not set header Content-Encoding="gzip".
else:
print('Content response headers (TRTH server): type: ' + r5.headers["Content-Type"] + ' - encoding: ' + r5.headers[
"Content-Encoding"] + '\n')
# Next 2 lines display some of the compressed data, but if you uncomment them save to file fails
# print ('20 bytes of compressed data:')
# print (r5.raw.read(20))
fileName = filePath + fileNameRoot + ".step5.csv.gz"
print('Saving compressed data to file:' + fileName + ' ... please be patient')
chunk_size = 1024
rr = r5.raw
with open(fileName, 'wb') as fd:
shutil.copyfileobj(rr, fd, chunk_size)
fd.close
print('Finished saving compressed data to file:' + fileName + '\n')
# Now let us read and decompress the file we just created.
# For the demo we limit the treatment to a few lines:
maxLines = 10
print('Read data from file, and decompress at most ' + str(maxLines) + ' lines of it:')
uncompressedData = ""
count = 0
with gzip.open(fileName, 'rb') as fd:
for line in fd:
dataLine = line.decode("utf-8")
# Do something with the data:
print(dataLine)
uncompressedData = uncompressedData + dataLine
count += 1
if count >= maxLines:
break
fd.close()
# Note: variable uncompressedData stores all the data.
# This is not a good practice, that can lead to issues with large data sets.
# We only use it here as a convenience for the next step of the demo, to keep the code very simple.
# In production one would handle the data line by line (as we do with the screen display)
# In[11]:
# Step 6 (cosmetic): formating the response received in step 4 or 5 using a panda dataframe
from io import StringIO
import pandas as pd
timeSeries = pd.read_csv(StringIO(uncompressedData))
timeSeries
# In[ ]:


