Skipping values lseg data platform

Hello, I am using the lseg data library for async data dumping for 60,000 RICs and I have encountered a problem that sometimes the response for some RICs does not return data.
I checked the availability of dumped indicators for specific RICs using workspace. These indicators are present, but when I request them to the API, they are not returned to me.
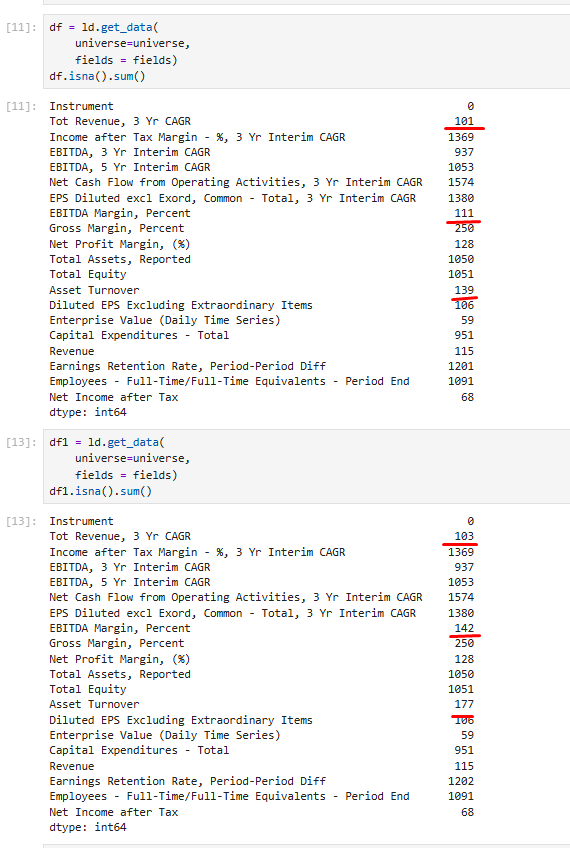
I have made several identical dumps and received a different number of missing values in the columns.
df.isna().mean() * 100

Accordingly, each time I did not receive data for some RICs. Here are the differences in data between dumps 1 and 3.

I am using dumping for 2500 RICs and an async function.
Code:
FIELDS = ['TR.TotRevenue3YrCAGR',
'TR.F.IncAftTaxMargPct3YrIntmCAGR',
'TR.EBITDA3YrInterimCAGR',
'TR.F.EBITDA5YrIntmCAGR',
'TR.F.NetCFOp3YrIntmCAGR',
'TR.F.EPSDilExclExOrdComTot3YrIntmCAGR',
'TR.EBITDAMarginPercent(Period=LTM)',
'TR.GrossMargin(Period=LTM)',
'TR.NetProfitMargin(Period=LTM)',
'TR.TotalAssetsReported(Period=FQ0)',
'TR.TotalEquity(Period=FQ0)',
'TR.AssetTurnover(Period=LTM)',
'TR.DilutedEpsExclExtra(Period=LTM)',
'TR.EV',
'TR.F.CAPEXTot(Period=LTM)',
'TR.Revenue(Period=LTM)',
'TR.EarningsRetentionRatePeriodToPeriodDiff',
'TR.F.EmpFTEEquivPrdEnd',
'TR.F.NetIncAfterTax(Period=LTM)']
PARAMS = {'Curn': 'USD', 'CH': 'Fd'}
response = await fundamental_and_reference.Definition(
universe=rics_batch,
fields=FIELDS,
parameters=PARAMS
).get_data_async()
Attached the log file for 1 and 3 unloading to the letter.
Can you recommend a solution to this problem?
Best Answer
-
I checked the log files and found that this could be the problem on the backend.
I can replicate this issue by sending requests to the RDP underlying platform.
config = ld.get_config() config.set_param("apis.data.datagrid.underlying-platform", "rdp") ld.open_session()I invoked the get_data method twice using identical parameters, but the returned results differ in the number of NA values.
I will raise this issue on your behalf to the backend team to verify what the problem is. The case number is 15200357.
0


Answers
-
Hello @inzilya
Please refer to this usage limits and guidelines document. With the number of instruments and the fields, you seem to be exceeding the allowed limit.
0 -
I ran 5 times the synchronous code where I sent requests of 1000 RIC every 2 seconds to explicitly avoid the request time limitation.
The volume of data received is 3 Mb.
I received about 7000 data points per request, although in my version there is no limit on the number of data points.(for example, if the request asked for 5000 instruments, but only 3000 were returned)All 60,000 RICs I sent a request for returned with data, but the problem remains that the number of missing values is still different.
The code provides for handling timeouts and server errors.
There are also cases when a completely empty column is returned in the response, for this situation there is a solution to handle it.
But when there is no data in a specific cell, it is very difficult to catch.
Even if you use additional loading for certain RICs, it may not return data for a specific RIC. In this case, how can I identify the lack of data in a cell? Is this due to the fact that a specific value is not in refenitiv or for some reason it did not reach me?
Can you suggest methods for identifying missing values in a cell or "data point"?Code:
FIELDS = ['TR.TotRevenue3YrCAGR', 'TR.F.IncAftTaxMargPct3YrIntmCAGR',
'TR.EBITDA3YrInterimCAGR', 'TR.F.EBITDA5YrIntmCAGR',
'TR.F.NetCFOp3YrIntmCAGR', 'TR.F.EPSDilExclExOrdComTot3YrIntmCAGR'] response = fundamental_and_reference.Definition(
universe=rics_batch,
fields=FIELDS,
parameters=PARAMS
).get_data()
if response.is_success:
ld_df = response.data.dfDetect count of missing values:
missing_values_df = pd.DataFrame(data=df.replace("", np.nan).isna().mean() * 100).T.round(3)0 -
When you say synchronous - does the code wait for a response before proceeding with the next batch? Is the response taking more than 300 seconds (server timeout limit).
0 -
Of course it does, because the code works in main thread (synchronously), which will wait for a response from the server. And it will not move to the next batch until it receives a response.
The response from the server takes about 1-5 seconds. Depending on the number of fields in the request and the server load.
For all the time that I have been using this library, I have not had a timeout of 300 seconds.0 -
Can you provide the complete code and the instrument list. I will try to run it at my end.
0 -
import pandas as pd
from time import sleep
import lseg.data as ld
from lseg.data.content import fundamental_and_reference
from lseg.data.errors import LDError
def fetch_data(rics, fields, params):
ld.open_session()
df = pd.DataFrame()
step = 1000
for rics_list in range(0, len(rics), step):
attempt = 0
gotData = False
batch = rics[rics_list: rics_list + step]
while not gotData and (attempt < 3):
try:
response = fundamental_and_reference.Definition(
universe=batch,
fields=fields,
parameters=params
).get_data()
ld_df = response.data.df
df = pd.concat([df, ld_df], ignore_index=True)
print(f'got - {rics_list + step}')
gotData = True
# sleep(2)
except LDError as lde:
print(lde)
except Exception as e:
print(e)
sleep(5 * attempt + 10)
attempt += 1
ld.close_session()
return df
def main():
with open('rics.txt') as file:
rics = [line.strip() for line in file]
FIELDS = ['TR.TotRevenue3YrCAGR', 'TR.F.IncAftTaxMargPct3YrIntmCAGR',
'TR.EBITDA3YrInterimCAGR', 'TR.F.EBITDA5YrIntmCAGR',
'TR.F.NetCFOp3YrIntmCAGR', 'TR.F.EPSDilExclExOrdComTot3YrIntmCAGR']
PARAMS = {'Curn': 'USD', 'CH': 'Fd'}
result = fetch_data(rics, FIELDS, PARAMS)
result.to_csv('result.csv', header=True)
if __name__ == '__main__':
main()0 -
Thanks for the feedback. I hope the backend team can solve this problem.
Tell me where I can find the case number 15200357?0 -
I checked can found that the problem has been resolved.
However, the usage of the API should not exceed the 10,000 data point limit. Therefore, if you requested data for 20 fields, the number of items should be 500 or less than 500. For example:
df1 = ld.get_data( universe=universe[0:500], fields = fields)0


Categories
- All Categories
- 3 Polls
- 6 AHS
- 37 Alpha
- 167 App Studio
- 6 Block Chain
- 4 Bot Platform
- 18 Connected Risk APIs
- 47 Data Fusion
- 34 Data Model Discovery
- 710 Datastream
- 1.5K DSS
- 637 Eikon COM
- 5.3K Eikon Data APIs
- 19 Electronic Trading
- 1 Generic FIX
- 7 Local Bank Node API
- 11 Trading API
- 3K Elektron
- 1.5K EMA
- 260 ETA
- 571 WebSocket API
- 42 FX Venues
- 16 FX Market Data
- 2 FX Post Trade
- 1 FX Trading - Matching
- 12 FX Trading – RFQ Maker
- 5 Intelligent Tagging
- 2 Legal One
- 26 Messenger Bot
- 4 Messenger Side by Side
- 9 ONESOURCE
- 7 Indirect Tax
- 60 Open Calais
- 285 Open PermID
- 47 Entity Search
- 2 Org ID
- 1 PAM
- PAM - Logging
- 6 Product Insight
- Project Tracking
- ProView
- ProView Internal
- 25 RDMS
- 2.3K Refinitiv Data Platform
- 17 CFS Bulk File/TM3
- 934 Refinitiv Data Platform Libraries
- 5 LSEG Due Diligence
- 1 LSEG Due Diligence Portal API
- 4 Refinitiv Due Dilligence Centre
- Rose's Space
- 1.2K Screening
- 18 Qual-ID API
- 13 Screening Deployed
- 23 Screening Online
- 12 World-Check Customer Risk Screener
- 1K World-Check One
- 46 World-Check One Zero Footprint
- 46 Side by Side Integration API
- 2 Test Space
- 3 Thomson One Smart
- 10 TR Knowledge Graph
- 151 Transactions
- 143 REDI API
- 1.8K TREP APIs
- 4 CAT
- 27 DACS Station
- 126 Open DACS
- 1.1K RFA
- 108 UPA
- 197 TREP Infrastructure
- 232 TRKD
- 924 TRTH
- 5 Velocity Analytics
- 9 Wealth Management Web Services
- 106 Workspace SDK
- 11 Element Framework
- 5 Grid
- 19 World-Check Data File
- 1 Yield Book Analytics
- 48 中文论坛